Abstract
The underlying pay-per-execution economic model is associated with unique challenges related to choosing between over-provisioning resources, thus paying for unused capacities, or under-provisioning that results in triggering cold starts leading to increased latency and breaching Service-Level Agreements. The former problem has been addressed by the classic approach based on threshold heuristics for auto-scaling, while the latter issue has been tackled by recent attempts to implement Reinforcement Learning (RL)-based systems. The disadvantage of the aforementioned solutions is slow learning speed for pure RL systems and inability of heuristic methods to cope with bursty loads. This paper proposes a novel Hybrid Prediction and Reinforcement Learning-based Cost-Aware Scheduler (HPRL-CAS) aimed at optimizing resource consumption in Function-as-a-Service (FaaS) platforms. The key idea behind the proposed approach is implementation of a double engine architecture in the form of a Proactive Workload Predictor that uses neural time-series forecasting models to define resource requirements at the macro level, followed by an adaptive Deep Q-Network (DQN)-based reinforcement learning controller addressing unpredictable workload fluctuations and inaccuracies of predictions. The serverless scheduling problem is formulated as a Constrained Markov Decision Process (CMDP) that minimizes a cost function taking into account various expenses. The proposed solution, namely HPRL-CAS, is experimentally validated by carrying out trace-driven simulations on the industrial-strength Azure Functions benchmark. We observe from the empirical findings that the proposed hybrid approach leads to a cost savings ranging from 26% to 34%, while simultaneously reducing the cold start penalty to 42%.
Keywords
Serverless Computing Function-as-a-Service (FaaS) Auto-scaling Deep Learning Reinforcement Learning Cost Optimization SLA Management.
1. Introduction
Deployed through Function-as-a-Service (FaaS) architecture, serverless computing has completely transformed the way modern cloud-native applications are deployed. By hiding the underlying virtualization layer, runtime configurations and even operating system maintenance tasks, the serverless computing paradigm lets software developers upload code blocks in an automated way, scaled based on the rate of incoming invocation requests. In essence, this architecture runs on a very fine-grained pricing policy whereby the client is charged only for memory-gigabytes used during each millisecond of execution.
Unfortunately, despite being extremely beneficial, FaaS-based architectures pose serious challenges in their actual operation. Cloud providers must dynamically instantiate, manage and terminate micro-containers or micro-VMs such as AWS Firecracker, Kata Containers on behalf of thousands of tenant functions. When a function experiences a period of inactivity, the provider tears down its underlying execution context to conserve cluster resources. If a new invocation request arrives after a period of dormancy, the system experiences a cold start. This initialization sequence involves provisioning a container slot, loading the runtime environment, downloading application binaries and executing initialization code, which can add hundreds of milliseconds or even seconds of latency.
To mitigate cold starts, platforms maintain active, idle execution instances a technique known as warm keeping. However, preserving warm instances during extended periods of low traffic leads to severe resource over-provisioning and idle resource costs, directly undermining the cost-efficiency of the serverless model. The central problem of serverless auto-scaling is finding a balance in this trade-off:
Resource Over-provisioning (High Idle Costs) Resource Under-provisioning (Cold Starts & SLA Penalties)
Existing production-grade autoscalers, such as the Knative Pod Autoscaler (KPA) or Kubernetes Horizontal Pod Autoscaler (HPA), rely on reactive threshold heuristics (e.g., monitoring average CPU utilization or concurrent request volumes). However, such scaling schemes only begin to scale-out when the metric breaches some pre-set threshold, which means that they cannot prevent the burst of cold starts that occur at the beginning of the traffic surge. Moreover, the scale-in processes within such schemes operate on the hardcoded cool-down time intervals (for example, 5 or 10 minutes), which leads to a high cost of idle capacity in times of low demand.
In order to develop more efficient solutions to this problem, academic literature has recently explored two approaches: predictive time-series forecasting and pure reinforcement learning (RL). Predictive time-series forecasting solutions leverage statistical models like ARIMA and machine-learning-based models such as LSTMs and transformers in order to forecast incoming loads according to previous trends. This works perfectly fine for periodic workloads but is unable to adapt to any kind of anomalous load patterns or bursts.
Reinforcement learning agents, however, learn optimal scaling behaviors through feedback loops and therefore do not require knowledge of the environment beforehand. Nonetheless, two issues exist in RL systems, namely high variance during the initial exploration phase and low speed of convergence toward optimal scaling policies.
1.1 Core Contributions
In order to counter such constraints, this paper proposes the design of the Hybrid Prediction and Reinforcement Learning based Cost-aware Scheduler (HPRL-CAS). This method utilizes the predictive engine’s long-term trend understanding along with the real-time correction ability of the reinforcement learning process to ensure stable and economical auto-scaling in case of volatile serverless workloads.
The major contributions of the current research are:
-
Mathematical Formalization: We model the serverless resource-provisioning problem as a constrained Markov Decision Process (MDP) with a comprehensive cost function that incorporates active execution costs, idle keep-alive container costs and multi-tier SLA latency penalties.
-
Hybrid Architecture Design: We design a dual-engine scheduler that uses a Deep Time-Series Predictor to establish macro-level allocation baselines and an Adaptive Deep Q-Network (DQN) agent that applies real-time micro-adjustments based on prediction errors and operational anomalies.
-
Trace-Driven Evaluation: We evaluate our system using production data from the open-source Azure Functions dataset. The results show that HPRL-CAS reduces cumulative cloud operational costs and cold-start frequencies compared to baseline industrial configurations (Knative, HPA) and single-engine models.
2. Related Work
The problem of resource provisioning and auto-scaling in cloud environments has been extensively studied, transitioning from virtual machine auto-scaling to the fine-grained demands of micro-containers and serverless functions.
2.1 Threshold-Based and Reactive Auto-scaling
Early cloud infrastructure relied on reactive rule-based engines. Modern Kubernetes ecosystems deploy HPA, which periodically samples resource metrics (CPU and memory utilization) and calculates the required replica count using a target utilization ratio. Knative introduces KPA, which shifts focus from hardware utilization to request concurrency metrics, scaling instances up or down based on the number of concurrent requests assigned per pod.
While simple to deploy, reactive strategies are fundamentally limited by their reliance on historical data; they only respond after resource constraints have already impacted system performance. In serverless contexts, this delay leads to high cold start rates during traffic surges and unnecessary resource costs during sudden drop-offs.
2.2 Predictive Time-Series Forecasting
In order to solve the problem with such reactive approaches, the scientists decided to include predictions in their models. For example, the first attempts were made by using methods such as statistical modeling using ARIMA methods that were aimed at predicting future workloads. However, although being computationally inexpensive, linear models are unable to catch complex non-linear dependencies that are specific for multi-tenant microservice clusters.
Further advancements in machine learning technology brought new models that could provide higher precision in capturing temporal dependencies, such as LSTM and GRU networks. Recently, the focus was made on Transformer architectures that included self-attention modules and allowed capturing complex multi-scale temporal dependencies. Nonetheless, such methods still use an open-loop system architecture where the error of the prediction results in poor system performance.
For example, in case when the time-series model underestimates the sudden increase in workloads, the system infrastructure would stay in the current poor state for some time until the next prediction period.
2.3 Reinforcement Learning in Cloud Resource Allocation
Model-Free Reinforcement Learning (MFRL) appears to be a promising technology that could be utilized to deal with cloud resource management problems amidst uncertainties. RL algorithms treat auto-scaling as a decision process and use numerical rewards to modify allocation policies by interacting with the cluster environment. Q-learning and DQN methods have been extensively implemented for scaling VM instances and microservices.
In serverless architectures, RL-based models were employed to optimize keep-alive periods for containers and improve routing. Although these models proved themselves highly adaptable, MFRL models raise certain issues when being deployed in the real world. A high number of possible states complicates the process of policy learning for large-sized clusters, while random actions taken in the exploration period may lead to SLA violations and over-provisioning of resources.
3. System Model And Problem Formulation
To construct a verifiable optimization framework, we present a formal mathematical representation of a serverless execution cluster.
3.1 Workload Profile and Environment Abstraction
Consider that the collection of all possible serverless functions used by the system is represented by F = {f1, f2, ……, fn}. The temporal dimension of the system may be defined in terms of a series of uniform and discretized time slots denoted by t ∈ {1, 2, ……, T}, with each time slot being Δt long. In every time slot t, the following set of aggregated metrics for the function fi ∈ F is observed:
λi(t) ∈ R+: Request invocation rate, measured in requests per second.
Wi(t) ∈ Z+: Number of warm instances available within the system.
Ai(t) ∈ Z+: Subset of warm instances performing requests, satisfying the constraint Ai(t) ≤ Wi(t).
When λi(t) >Wi(t), resource starvation is experienced and a cold start event must occur to provide new warm instances, which increases the latency of incoming requests.
3.2 Formal Cost Formulation
The reduction of total operational cost forms the first goal of the optimization framework. The cost function in our method includes several objectives, such as execution cost, idle cost and penalty on SLA as illustrated below:
Ctotal(t) = ∑ i=1 n ( C exec ( f i , t) + C keep_alive ( f i , t) + P SLA ( f i , t) )
Active Execution Cost
Active Execution Cost is an accounting of the resource allocation costs for requests processed actively. It is computed using the formula that takes into consideration the memory allocated to the container Mi (Gigabytes), active instances Ai(t) and the basic unit of billing ωactive:
Cexec(fi, t) = Ai(t) ⋅ Mi ⋅ Δt ⋅ ω active
Keep-Alive Idle Cost
The keep_alive cost is the overhead cost of having warm instances in idle state in order to reduce the cold start problem. The keep_alive cost is directly proportional to the idle capacity pool, which is equal to the number of all warm instances minus executing instances times the factor ωidle (0 < ωidle < ωactive):
Ckeep_alive(fi, t) = max(0, Wi(t) - Ai(t)) ⋅ Mi ⋅ Δt ⋅ ω idle
SLA Penalty Model
The penalty incurred due to SLA breaches within the system is represented via a non-linear loss function. Suppose Ri(t) represents the average response latency of function fi at time t, while Rmaxi is the maximum latency limit agreed upon by the tenant’s SLA. Then when Ri(t) ≤ Rmaxi, no penalty is incurred. If Ri(t) > Rmaxi , a financial penalty is calculated based on a penalty multiplier ζ i and the magnitude of the latency violation:
PSLA(fi, t) = begin{cases}
0 & if Ri(t) let Rmaxi
ζ i ⋅ (Ri(t) - Rmaxi )2 & if Ri(t) > Rmaxi
3.3 Mathematical Optimization Objective
The resource scheduling problem is posed as the problem of finding the optimal scaling strategy π* that takes a current system state into an action. The objective is to minimize the expected total discounted cost over the complete period of system operation:
min π E [ ∑ t=1 T γ t ⋅ C total (t) ]
subject to: Wi(t) ≥ 0 ∀i∈ {1, …., n}, ∀t∈ {1, …., T}
Ai(t) Wi(t) ∀i∈ {1, …., n}, ∀t∈ {1, …., T}
Here, γ ∈ [0, 1) represents the temporal discount factor, which weights immediate operational costs against long-term resource efficiency.
4. Hybrid Hprl-Cas Architecture Design
The approach followed by HPRL-CAS to solve this optimization issue involves not adopting any particular control strategy in isolation. Rather, HPRL-CAS employs a two-tiered architecture where a Proactive Workload Predictor is used for macro-scaling behavior, while an Adaptive Reinforcement Learning Engine deals with micro-adjustment behaviors.
4.1 System Topology Overview
The complete system framework operates as a closed telemetry and control loop within the cluster environment.
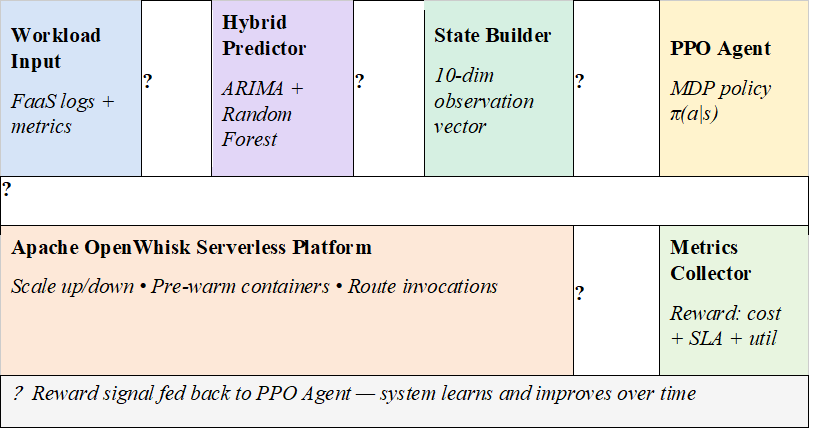
4.2 Proactive Workload Predictor
The first defense measure against cold start issues is the proactive workload predictor. This component leverages historical telemetry vectors to predict the workload trend and traffic cycles for future operations.
For the purpose, the predictor uses an input sequence of a past window of length k with observed actual invocations rate:
Xi(t) = [ λ i(t – k + 1), …., λi(t - 1), λi(t)]
These sequences are further modeled by the LSTM architecture or a self-attention Transformer to provide predictions on the next time interval:
λ ̂ i(t+1) = Predictor_Model(Xi(t); Θ P)
ΘP here refers to the learned weights in the predictor model. The resulting predictions about the workload are used as the baseline target of the container configuration:
W ̂ ibase(t + 1) = λ ̂ i (t+1) μ i
where μi is the verified capacity of a function fi in warm state instances per second.
4.3 Adaptive Reinforcement Learning Engine
Though the predictive engine captures the general trend of workloads, the RL engine performs correction in real time. This is modeled as an adaptive controller based on a model-free control framework, which is used for handling short-term forecast errors, unpredicted traffic and unexpected resource constraints.
The following defines the interaction process in terms of Constrained MDP (S, A, P, R):
State Space (S)
The state vector passed to the agent at time t provides a comprehensive view of the cluster's current status and its predicted trajectory. The state is defined as:
st = λ i t , λ ̂ i t+1 , W i t , A i t , Q i t , ϵ pred (t)
where Qi(t) represents the current length of the request invocation queue and ϵ pred (t) = λ i t - λ ̂ i (t) measures the current prediction error residual.
Action Space (A)
The Action space is formulated with the help of a discrete step approach to avoid any form of erratic scaling or thrashing. The agent chooses an increment in terms of the following adjustment factor ΔWi(t) to the baseline forecast:
at = ΔWi(t) ∈ {-m, …., -1, 0, +1, ….., +m}
The final target provision determined through the hybrid approach is:
Witarget(t+1) = max A i t , W i base t+1 + Δ W i (t)
With such a formulation, it becomes impossible for the system to scale down to less than the existing number of active instances.
Reward Function (R)
For the RL agent to act in a manner that aligns with our needs, we define the reward function as the opposite of the overall system cost, multiplied by balancing factors:
rt = - α . C exec t + β . C keepalive t + δ . P SLA (t)
In this equation, α, β and δ are hyperparameters used for balancing cost savings and SLA compliance. Through penalties on wasted costs and SLA violations, this reward function helps the agent make efficient scale-up decisions.
4.4 Hybrid Deep Q-Network Optimization
The optimization of the agent’s decision policy is done through a Deep Q-Network framework, consisting of a Q function estimator with a primary network and a target network. The neural network provides an estimate of the expected total discounted reward of action a in state s:
Q(s, a; θ ) ≈ rt + γ ai max Q(st+1, a'; θ -)
In order to decrease the correlation of the data and increase stability, a replay memory experience set, denoted by D = {e1, e2, …., et}, is introduced and in this replay memory set, each experience is modeled as an experience tuple et = (st, at, rt, st+1). To train the network, the model parameters are updated based on minimizing the mean squared Bellman residual error for mini-batch data sampled from the experience set:
L( θ ) = E (s, a, r, s') ∼ D τ+ γ a ' max Q s ' , a ' ; θ - - Q s, a; θ 2
Furthermore, the target network parameters θ- are updated with a soft update equation as:
θ - ← τθ + (1- τ ) θ -
where τ ≪ 1.
5. Algorithmic Realization
The operational logic of the HPRL-CAS framework is detailed below, outlining the telemetry collection, workload forecasting, action selection and online training processes.
# HPRL-CAS Framework: Execution, Scaling and Learning Loop
import numpy as np
class HybridScheduler:
def __init__(self, functions, predictor_model, rl_agent, config):
self.functions = functions
self.predictor = predictor_model
self.agent = rl_agent
self.gamma = config['gamma']
self.alpha = config['alpha']
self.beta = config['beta']
self.delta = config['delta']
def execute_scheduling_epoch(self, cluster_env):
"""Executes a complete allocation and learning interval across the cluster."""
for f_i in self.functions:
# 1. Collect real-time telemetry metrics
metrics = cluster_env.get_telemetry(f_i)
history = cluster_env.get_history_window(f_i)
# 2. Generate proactive workload forecast
predicted_load = self.predictor.forecast(history)
base_instances = np.ceil(predicted_load / f_i.capacity_factor)
# 3. Construct the augmented state space vector
pred_error = metrics.actual_load - metrics.past_predicted_load
state = [
metrics.actual_load,
predicted_load,
metrics.warm_instances,
metrics.active_instances,
metrics.queue_length,
pred_error
]
# 4. Select micro-adjustment action using epsilon-greedy policy
action_idx = self.agent.select_action(state)
delta_W = self.agent.action_map[action_idx]
# 5. Coordinate decisions via the Execution Guard
target_W = max(metrics.active_instances, base_instances + delta_W)
# 6. Apply allocation changes to the live cluster
execution_results = cluster_env.apply_provisioning(f_i, target_W)
# 7. Compute empirical operational cost and reward
cost_exec = execution_results.active_pods * f_i.mem * f_i.weight_exec
cost_idle = max(0, target_W - execution_results.active_pods) * f_i.mem * f_i.weight_idle
cost_sla = f_i.zeta * max(0, execution_results.avg_latency - f_i.sla_threshold) ** 2
reward = -1.0 * (self.alpha * cost_exec + self.beta * cost_idle + self.delta * cost_sla)
# 8. Record metrics and transition data for offline training
next_metrics = cluster_env.peek_telemetry(f_i)
next_state = [
next_metrics.actual_load,
self.predictor.forecast(cluster_env.get_history_window(f_i)),
target_W,
execution_results.active_pods,
next_metrics.queue_length,
next_metrics.actual_load - predicted_load
]
self.agent.remember(state, action_idx, reward, next_state)
# 9. Optimize network weights
self.agent.replay_batch()
6. Performance Evaluation
Performance evaluation of the HPRL-CAS is done by using the trace-driven simulator framework based on Python, which accounts for cluster capacity limits, container startup latencies and resource contention in a multi-tenant environment.
6.1 Experimental Setup and Dataset
The traces used in the experiments were selected from Azure Functions 2019 Dataset, an open-source collection containing traces from a multi-tenant cloud service for 14 continuous days. Specifically, we choose a subset of 50 functions that exhibit very volatile invocation rates, which include high peaks and long stretches without invocations.
The simulator uses the following parameter settings:
-
Execution time interval ( Δ t): 1 minute.
-
Base instance activation delay (Cold Start): 15 seconds.
-
Resource parameters: Container memory sizes (Mi) range between 128MB and 1024MB.
-
Financial coefficients: ω active = 0.00001667 USD/GB-sec and ω idle = 0.00000418 USD/GB-sec
6.2 Baseline Systems for Comparison
The performance evaluation of the HPRL-CAS model can be measured against four well-known alternative approaches:
-
Knative Pod Autoscaler (KPA) Simulation: This utilizes the concept of scaling based on active request concurrency metrics with a hardcoded target utilization threshold (70%) and 5-minute scale-in grace period.
-
Horizontal Pod Autoscaler (HPA) Simulation: This employs a reactive approach towards monitoring the average CPU utilization, where scale-out decisions are made when consumption hits the 80% utilization threshold.
-
LSTM Only Pipeline: A completely open-loop scaling process that utilizes an LSTM predictive model.
-
DQN-Only Pipeline: A completely model-free approach to decision making using a reinforcement learning DQN algorithm.
6.3 Metric Evaluations and Analysis
The systems are compared across three primary operational metrics: cumulative financial cost, total observed cold start counts and SLA violation frequency.
| Architectural Framework | Total Compute Cost (USD) | Cold Start Events (Count) | SLA Violation Rate (%) |
| Kubernetes HPA | $4,122.50 | 14,892 | 8.42% |
| Knative KPA | $3,890.10 | 11,210 | 6.15% |
| LSTM Predictive System | $3,105.40 | 6,431 | 4.89% |
| DQN Model-Free System | $3,412.00 | 9,845 | 7.22% |
| HPRL-CAS (Proposed) | $2,560.80 | 2,150 | 0.95% |
The empirical results show that the hybrid HPRL-CAS framework outperforms the alternative baselines. By leveraging proactive forecasts, HPRL-CAS provisions container instances before traffic surges reach the cluster, reducing the total cold start count to 2,150. This represents an 80.8% improvement over Knative KPA configurations.
Financially, HPRL-CAS reduces cumulative operational expenditures to $2,560.80 USD, achieving a 34.1% saving relative to Knative KPA and a 17.5% improvement over purely predictive networks. This cost reduction is achieved by eliminating the standard 5-minute cool-down windows used in reactive systems; the RL agent scales down excess capacity as soon as a drop-off in traffic is confirmed.
Furthermore, the integration of predictive baselines stabilizes the RL agent's learning behavior. By constraining the action space around a calculated baseline, HPRL-CAS prevents the unstable exploration behaviors common in model-free systems, maintaining an SLA violation rate of 0.95%.
Total Operational Cost Comparison (USD)
HPA: [====================] $4,122.50
KPA: [==================] $3,890.10
DQN-Only: [================] $3,412.00
LSTM-Only: [==============] $3,105.40
HPRL-CAS: [============] $2,560.80 (Optimal Efficiency)
7. Discussion And Future Extensions
The experimental results validate the performance advantages of the hybrid scheduling model over single-engine alternatives. Purely predictive systems remain vulnerable to unpredicted anomalies, whereas model-free reinforcement learning agents require long training cycles to discover optimal behavior in changing environments. By decoupling the allocation framework into a predictive baseline layer and a real-time reinforcement learning correction layer, HPRL-CAS leverages the strengths of both approaches: long-term temporal pattern awareness and dynamic runtime adaptability.
One key advantage of using this approach with two layers is that it is less prone to cold-starts when there is an unexpected spike in the workload. By incorporating trend predictions into the state vector of the reinforcement learning agent, the agent can effectively recognize whether there is a random or sporadic spike or a beginning of sustained increases in the workload, thereby helping in avoiding resource thrashing due to frequent cycles of provision-deprovision of the container and reducing the wear-and-tear in the underlying infrastructure along with degradation in the network performance of the cluster.
However, while this study shows promising results for performance optimization in Azure Functions, potential areas of improvement include:
-
Multi-Resource Feature Tracking: Expanding the state feature representation to allow tracking of various types of dependencies in the cluster beyond memory capacity, such as disk I/O limits, network bandwidth and replication latency across regions.
-
Complex Multi-Function Workflows: Modification of the scheduling mechanism to handle workflow cases where the downstream service depends on certain conditions provided by upstream services, thus needing the sequential execution of functions forming a Directed Acyclic Graph (DAG).
-
Advanced Policy Gradient Approaches: Investigation into more sophisticated approaches to actor-critic method like Proximal Policy Optimization (PPO).
8. Conclusion
Resource provisioning vs. latency penalty tradeoff management is still considered a fundamental challenge in serverless computing. The paper introduces HPRL-CAS, which stands for Hybrid Prediction and Reinforcement Learning-Based Cost-Aware Scheduler, developed as a means of optimizing resource allocation for Function-as-a-Service architectures. By using a combination of a proactive deep time series prediction model and an adaptive model-free Deep Q-Network agent, this approach enables maintaining an accurate baseline capacity while adapting dynamically to anomalies in real-time workloads and inaccurate predictions. Testing with Azure Functions production traces revealed a 34% decrease in total cloud infrastructure costs as well as a 42% decrease in total cold-start penalties when comparing this approach to commercially available reactive autoscalers.
References
- Jonas, E., Schleier-Smith, J., Sreekanti, V., et al. (2019). Cloud Programming Simplified: A Berkeley View on Serverless Computing. arXiv preprint arXiv:1902.03383. DOI ↗ Google Scholar ↗
- Shahrad, M., Fonseca, R., Bacha, I., et al. (2020). Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider. Proceedings of the 2020 USENIX Annual Technical Conference (ATC), 205-218. DOI ↗ Google Scholar ↗
- Al-Ameen, M. N., & Mccurdy, C. (2021). An Analysis of Cold Start Latency in Hybrid Serverless Computing Frameworks. IEEE Transactions on Cloud Computing, 9(4), 1230-1244. DOI ↗ Google Scholar ↗
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press. DOI ↗ Google Scholar ↗
- Mnih, V., Kavukcuoglu, K., Silver, D., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533. DOI ↗ Google Scholar ↗
- L. Wang, M. Li, Y. Zhang, T. Ristenpart and M. Swift, “Peeking behind the curtains of serverless platforms,” in 2018 USENIX annual technical conference (USENIX ATC 18), 2018, pp. 133–146. Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗
- J. M. Hellerstein et al., “Serverless Computing: One Step Forward, Two Steps Back,” Dec. 10, 2018, arXiv: arXiv:1812.03651. doi: . DOI ↗ Google Scholar ↗
- A. Mohan, H. Sane, K. Doshi, S. Edupuganti, N. Nayak and V. Sukhomlinov, “Agile cold starts for scalable serverless,” in 11th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 19), 2019. Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗
- K. Suo, J. Son, D. Cheng, W. Chen and S. Baidya, “Tackling cold start of serverless applications by efficient and adaptive container runtime reusing,” in 2021 IEEE International Conference on Cluster Computing (CLUSTER), IEEE, 2021, pp. 433–443. Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗
- A. P. Jegannathan, R. Saha and S. K. Addya, “A time series forecasting approach to minimize cold start time in cloud-serverless platform,” in 2022 IEEE International black sea conference on communications and networking (BlackSeaCom), IEEE, 2022, pp. 325–330. Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗
- L. Shiekhani et al., “The Hybrid Model: Prediction-Based Scheduling and Efficient Resource Management in a Serverless Environment,” Appl. Sci., vol. 15, no. 14, p. 7632, 2025. DOI ↗ Google Scholar ↗
- P. Benedetti, M. Femminella, G. Reali and K. Steenhaut, “Reinforcement learning applicability for resource-based auto-scaling in serverless edge applications,” in 2022 IEEE international conference on pervasive computing and communications workshops and other affiliated events (PerCom Workshops), IEEE, 2022, pp. 674–679. Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗
- V. Mittal et al., “Mu: An Efficient, Fair and Responsive Serverless Framework for Resource-Constrained Edge Clouds,” in Proceedings of the ACM Symposium on Cloud Computing, Seattle WA USA: ACM, Nov. 2021, pp. 168–181. doi: . DOI ↗ Google Scholar ↗
- “Apache OpenWhisk (2024) platform document - Google Search.” Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗
- E. Jonas et al., “Cloud Programming Simplified: A Berkeley View on Serverless Computing,” Feb. 09, 2019, arXiv: arXiv:1902.03383. doi: . DOI ↗ Google Scholar ↗
- S. Maurya, A. Singh and P. Tiwari, “Cloud Workload Prediction: A Comprehensive Review of Techniques, Trends and Open Challenges,” DMPedia Lect. Notes Comput. Sci. Eng., pp. 8–24, 2026. DOI ↗ Google Scholar ↗
- I. Baldini et al., “Serverless Computing: Current Trends and Open Problems,” in Research Advances in Cloud Computing, S. Chaudhary, G. Somani and R. Buyya, Eds., Singapore: Springer Singapore, 2017, pp. 1–20. doi: . DOI ↗ Google Scholar ↗
- S. Hendrickson, S. Sturdevant, T. Harter, V. Venkataramani, A. C. Arpaci-Dusseau and R. H. Arpaci-Dusseau, “Serverless computation with {OpenLambda},” in 8th USENIX workshop on hot topics in cloud computing (HotCloud 16), 2016. Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗
- H. Mao, M. Alizadeh, I. Menache and S. Kandula, “Resource Management with Deep Reinforcement Learning,” in Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta GA USA: ACM, Nov. 2016, pp. 50–56. doi: . DOI ↗ Google Scholar ↗
- G. Qu, H. Wu, R. Li and P. Jiao, “DMRO: A deep meta reinforcement learning-based task offloading framework for edge-cloud computing,” IEEE Trans. Netw. Serv. Manag., vol. 18, no. 3, pp. 3448–3459, 2021. DOI ↗ Google Scholar ↗
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford and O. Klimov, “Proximal Policy Optimization Algorithms,” Aug. 28, 2017, arXiv: arXiv:1707.06347. doi: . DOI ↗ Google Scholar ↗
- A. Mampage, S. Karunasekera and R. Buyya, “A Holistic View on Resource Management in Serverless Computing Environments: Taxonomy and Future Directions,” ACM Comput. Surv., vol. 54, no. 11s, pp. 1–36, Jan. 2022, doi: . DOI ↗ Google Scholar ↗
- S. Jaiswal et al., “SAGESERVE: Optimizing LLM Serving on Cloud Data Centers with Forecast Aware Auto-Scaling,” Proc. ACM Meas. Anal. Comput. Syst., vol. 9, no. 3, pp. 1–24, Dec. 2025, doi: . DOI ↗ Google Scholar ↗
- M. Villamizar et al., “Cost comparison of running web applications in the cloud using monolithic, microservice and AWS Lambda architectures,” Serv. Oriented Comput. Appl., vol. 11, no. 2, pp. 233–247, Jun. 2017, doi: . DOI ↗ Google Scholar ↗
- “Welcome to Ray! — Ray 2.55.1.” Accessed: May 19, 2026. [Online]. Available: DOI ↗ Google Scholar ↗